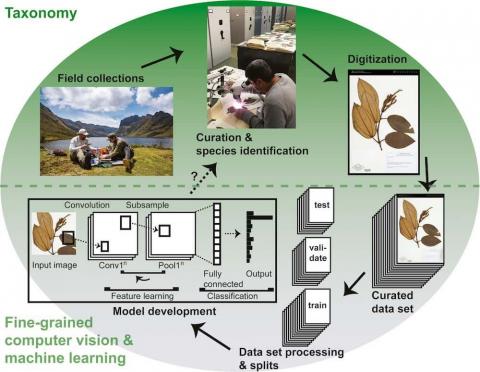
Cataloguing plant diversity and describing new species is a critical and ongoing task that is hampered by a dearth of expertise and an inherently slow process. Even under ideal conditions, collecting a specimen in the wild, describing it as a new species, and publishing that description can take one to two years. More often, it can take decades. Herbaria worldwide are home to a backlog of as many as a million unidentified specimens, and are thought to already contain the majority of undescribed plant species. Computer algorithms taking advantage of machine learning, trained on high quality annotated datasets, could be a key part of the solution.
In a new article published in Applications in Plant Sciences’ Machine Learning in Plant Biology special issue, lead author Damon P. Little and colleagues sought ways to harness this potential. The authors hosted a competition on the Kaggle data science platform to develop an automatic species identification algorithm using machine learning. The group put forward a data set for training that included over 46,000 imaged herbarium specimens representing 683 species of the family Melastomataceae. As is typical for herbarium collections, some of these species were represented by many specimens, and others by relatively few.